
Every day, a bevy of information is made available in the field of biology: genetic sequences, patterns in protein activity, medical scans (MRI, PET, CAT, etc.). In order to keep up with the rapid pace of research, and its unparalleled production levels of data, the field of bioinformatics was created.
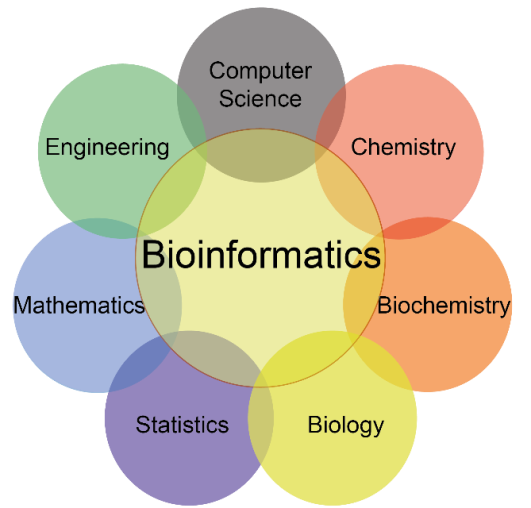
Bioinformatics is an interdisciplinary field of study focused on the acquisition, storage, and archiving of biological data. It centers on the development and application of computational tools to analyze and interpret biological data. These typically comprise mathematical models, computer simulations, and analytical and theoretical methods to study behavioral, molecular, physiological, and social systems.
Below are some common applications of bioinformatics in biomedical research:
- Gene Finding and Sequence Similarity Searches
- Comparative genomics (i.e. in evolutionary studies)
- In vitro and virtual simulation experiments
- Development of genomic databases
- Studies in genetic expression
- Signal Transduction dynamics
- Population and human genetics
As can be seen, one of the most widespread applications of bioinformatics is genomic studies. For this reason, in order to become proficient in this field, it is necessary to have background knowledge in human genetics and the central dogma of molecular biology.
DNA is the primary substance comprising the human genome. It is a complex molecule, in the form of a double helix, whose individual units are known as nucleotides. Each nucleotide is composed of a Nitrogen base (Adenine, Thymine, Guanine, and Cytosine), a sugar molecule (deoxyribose), and a Phosphate group. The two strands are linked together by hydrogen bonds between the bases (Adenine with Thymine and Guanine with Cytosine). The proportion of Cytosine-Guanine pairs found in a sample determines the stability of the sample (if there is more Cytosine-Guanine), then the sample is said to be more stable.
The human genome has about 3.1 billion base pairs, amounting to about 10 Terabytes of data. In an era where big data has become a buzzword and has skyrocketed in importance, the genome is a definite object of the computational advances currently being made.
The central dogma of molecular biology, which is the core mechanism behind genomic studies and data, consists of the process in which DNA is used to manufacture protein.
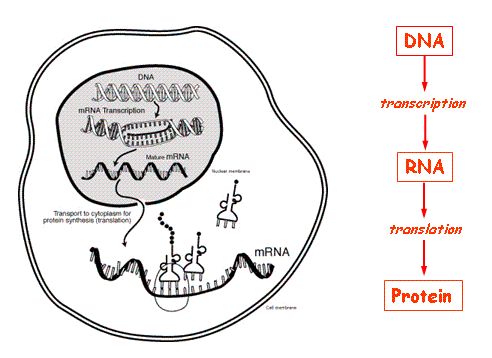
As can be seen above, this process begins with transcription, in which mRNA (messenger RNA, which is a nucleic acid serving as an intermediary between DNA and protein) is produced from the template strand. This sequence is later translated into polypeptide sequences in the ribosomes, which aggregate and fold into proteins, which, in turn, carry out the functions of the cell. Polypeptides are composed of chains of amino acids, which are coded for by individual units of RNA (and DNA before RNA) called codons ( units of 3 nucleotides). A single amino acid can be coded for by multiple codons, in a phenomenon known as the wobble effect. Thus, when a mutation (general term used to describe a change in genetic information) occurs in the DNA or RNA, it may not have any effect on the resulting protein.

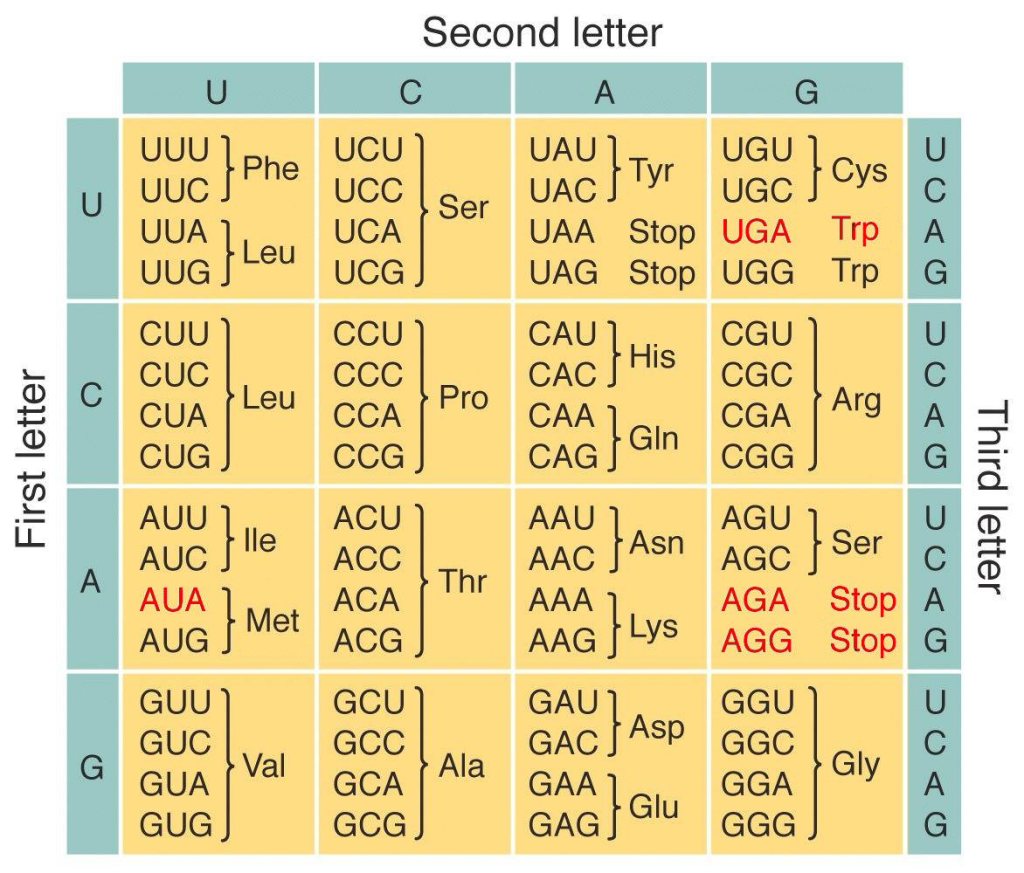
Interestingly, the corresponding amino acid for each codon seems to be very similar in every living organism, the reason for which it is often referred to as the universal genetic code.
This mechanism encodes every life process. The purpose of bioinformatics is to improve the understanding of these processes, starting at their beginning point, in order to better exploit them or understand the mechanisms behind their degradation (i.e. as in cancer).
